
In a struggle to tame Large Language Models
Initial excitement around Artificial Intelligence (AI) predictive abilities led to rapid investment in machine learning research and development of Large Language Models (LLMs) which sparked a wave of innovation in a variety of streams and at the same time revealed both the potential and limitations of early AI systems.
Introduction
This blog post will shortly recap what has been happening in the AI’s LLM space since the beginning from the author’s perspective and we will dive a little deeper into MCP, which stands for Model Context Protocol and has been in the hype recently in this space. MCP was introduced by Anthropic, a California based AI startup in late 2024. Why is MCP getting so popular and why are many of the Large language model (LLM) researchers, companies and individuals diving into this topic? Let’s dive in.
The initial WOW phase
When researchers and scientists found that LLMs can predict the next word or phrase reliably, that was the eye-opening moment. An example of how LLMs can predict next tokens is shown below, when the user just types the letters “Glo” , the user is offered with relevant suggestions.

This simple word prediction trick when applied to huge datasets unlocked new and valuable application areas. For end users this meant that the LLMs were not only able to predict what a user might think, but also answer hard questions. From that point till now we have been trying to tame LLMs to make them work the way we want.
Initially, the focus was on chat-based language models because they excelled at tokens/words prediction. These models were trained on vast amounts of text data and learned to understand patterns in language, making them highly effective at tasks like conversation, text completion, and natural language understanding.

As the technology progressed, researchers and developers began expanding beyond pure text applications leading to the development of models that could understand, generate and manipulate visual content.
Augmentation phase
At the beginning, it became clear that retraining large models was not feasible for everyone due to the immense computational resources and expertise required. As a solution, a method called Retrieval-Augmented Generation (RAG) was developed, which enables the model to access relevant data sources in real time rather than relying solely on pre-trained knowledge.

This approach allowed the model to retrieve relevant information from private datasets and incorporate that context into its responses, improving accuracy and relevance. By using RAG, the model can generate more informed and contextually aware outputs, without the need for constant retraining, making it more flexible and adaptable to specific tasks or queries. However, RAG has challenges with retrieval accuracy, adds more latency and is harder to debug.
Function-calling Phase
Another significant breakthrough occurred with the introduction of function/tool calling, where LLMs were able to invoke functions dynamically, based on specific needs or contexts. This addressed some of the drawbacks with RAG, for example, the model can invoke precise methods, the retrieval accuracy improved with lesser latency and ease of debugging.
Eventually Anthropic standardized the way the invocation happens and MCP came into existence. This integration opened up new possibilities for automating workflows and enhanced decision-making processes by enabling the model to seamlessly interact with external systems and execute tasks autonomously or on demand. Let's dive a little deeper.
MCP under the hood
How are AI models able to invoke tools, also known as functions?
Models are trained to do a "function call" when they need more data. It is important to know that models in use need to be trained for this purpose, though this is more common with most of the models these days. This can be configured to auto or explicit modes. Models do this by generating a JSON output that represents the input parameters that this function needed and get in return the function output. And the function call needs to be declared to the model using a JSON Schema so the model can understand the features it represents, required input and what it gets in return. An example snippet below:

Also most of the time you may add some system prompt to guide the model to use the functions you made available.
So let's take a look at what steps are needed to get an MCP server in place.
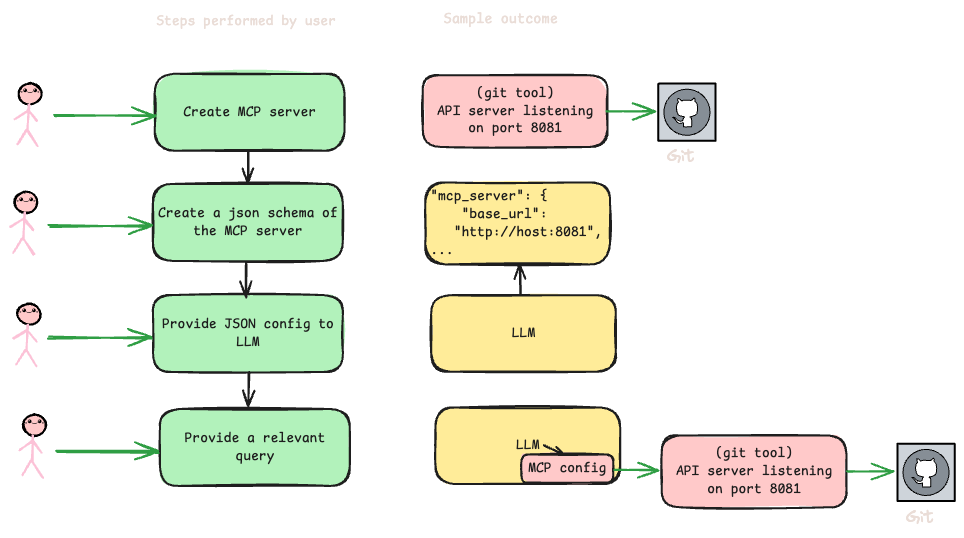
So, essentially, in this case, the MCP server is an API server which can perform some git actions. To make your model call this one, firstly a MCP server needs to be created and accessible over the network. They can be community hosted as well. After that, config JSON needs to be created and updated to the LLM. After which, the LLM invokes the server if need be based on the user’s query. Learn more about function calling in OpenAI documentation.
Also, this started to be an eco-system and loads of MCP servers were implemented from the commercial and community groups. Some of those are collected under MCP servers collection in GitHub.
Applications of MCP
Multiple MCP servers can be connected to a single LLM or multiple LLMs, each capable of being autonomously triggered with different parameters, working together in a coherent way. They could be a Search Engine Optimiser (SEO) with MCP for a single website or an aggregator across a bunch of websites. Technically speaking, any software product can implement an MCP server to enable direct integration to LLMs and LLMs can augment the knowledge, make additions, modifications directly to those products.
An example below shows a git tool, a web tool and a file tool configured to use for a given LLM. Imagine as a developer, if you just provide the requirements in simple plain text, the model tries to use its own knowledge and reaches out to the needed tools and finally gets back with a fully finished work available in version control. This could be placed in a continuous loop to obtain better results which LLM itself can improve on without human intervention autonomously. Developing a feature in software development used to take days if not weeks before this concept existed. As a result, certain coding editors like Cursor, Windsurf, Microsoft Copilot and Bolt gained popularity and this type of coding was named vibecoding by Andrey Karpathy.

Where are we today
Taking a step back, so far, we have reached a level where we can invoke functions based on the scenario or input provided to LLMs. This capability has fundamentally transformed how AI systems can interact with the world around them. This has already exploded with wide possibilities, enabling LLMs to perform complex actions based on natural language understanding. Now there are systems which have multimodal and multiagent systems that can process images alongside text, understand spoken commands, and generate content across different formats simultaneously. Multi-agent architectures have further revolutionized the field by enabling specialized AI entities to collaborate, debate, and collectively solve problems that would be challenging for a single person or even a development team.
Challenges
This being still in a very early stage, there are a significant number of errors, bugs, vulnerabilities, license violations, and other issues around this. Given the nature of these technologies, robust solutions addressing security vulnerabilities and privacy concerns remain in early development phases. Also, as the lack of tooling for monitoring and troubleshooting around these systems cause challenges with traceability, predictability etc. Considering the hype, these agents are not autonomous enough to perform complex tasks without human intervention. This is also due to the fact that AI agents are not able to have a thought process like humans as of today. This makes AI still not very useful for mission-critical or common real-life use cases involving emotional intelligence, creative ability and ethical reasoning or judgements.
Where are we heading to
The environment is still dynamic and moving at a fast pace. It's hard to predict which direction it will take in the coming weeks, months or years. Some companies like Nvidia, Google claim that we will be reaching AGI (Artificial General Intelligence, sometimes called human level intelligence AI) in less than 5 years, but the feeling I have is that we are still in the process of taming the LLMs to make it work in a way we want.
That said, companies like OpenAI, Anthropic, Meta, Google and others are trying hard to release amazing features every month improving their models on a mission to become first to achieve AGI to lead the AI market space.
More reading
1. Introduction for MCP - Model context protocol introduction
2. Function calling - OpenAI function calling explained
3. MCP servers collection - Github repository with the list of MCP servers
4. Vibe-coding - Andrey Karpathy - Introduction to MCP from Anthropic

Anoop Vijayan is a Senior Cloud Architect who has decades of experience working in Cloud, DevOps, Continuous Integration and Continuous Delivery systems.